Dog breed recognition web app
Introduction
In this post I wanted to show off the web app I made with my group for the Team Software Engineering module. We decided to make a web app which allows people to upload a photo of a dog and predict its breed. It is available here.
What did we build?
We built an app that allow users to upload an image of a dog. Then the application will identify the dog, outputting a plethora of information including what foods it can and cannot eat, as well as its common health problems.
Language and libraries used
The application was created using Python as this has a variety of libraries such as TensorFlow which is ideal for deep learning because it sets up training with datasets. TensorFlow was used because it gave the team access to Keras which was more compatible with beginners due to its considerable power like Pytorch (another popular framework), however Pytorch is tailored for experienced machine learning developers since it allows in depth customisation of the model.
Dataset used
The dog breed dataset used to train the model was acquired from the website Kaggle, including over 10,000 images across 120 different dog breeds, a sufficient range to help train the application effectively. The dataset can be accessed here
Front End adjustments
To successfully make the website appear as professional as possible, it followed commercial standards. One common standard of modern websites implemented was a hero image. This has been accomplished as these types of images immediately capture the user’s attention and encourages them to explore the website and its contents further. Additionally, the website was made to be responsive, meaning that regardless of what device or window size, the user-experience will be consistent throughout.
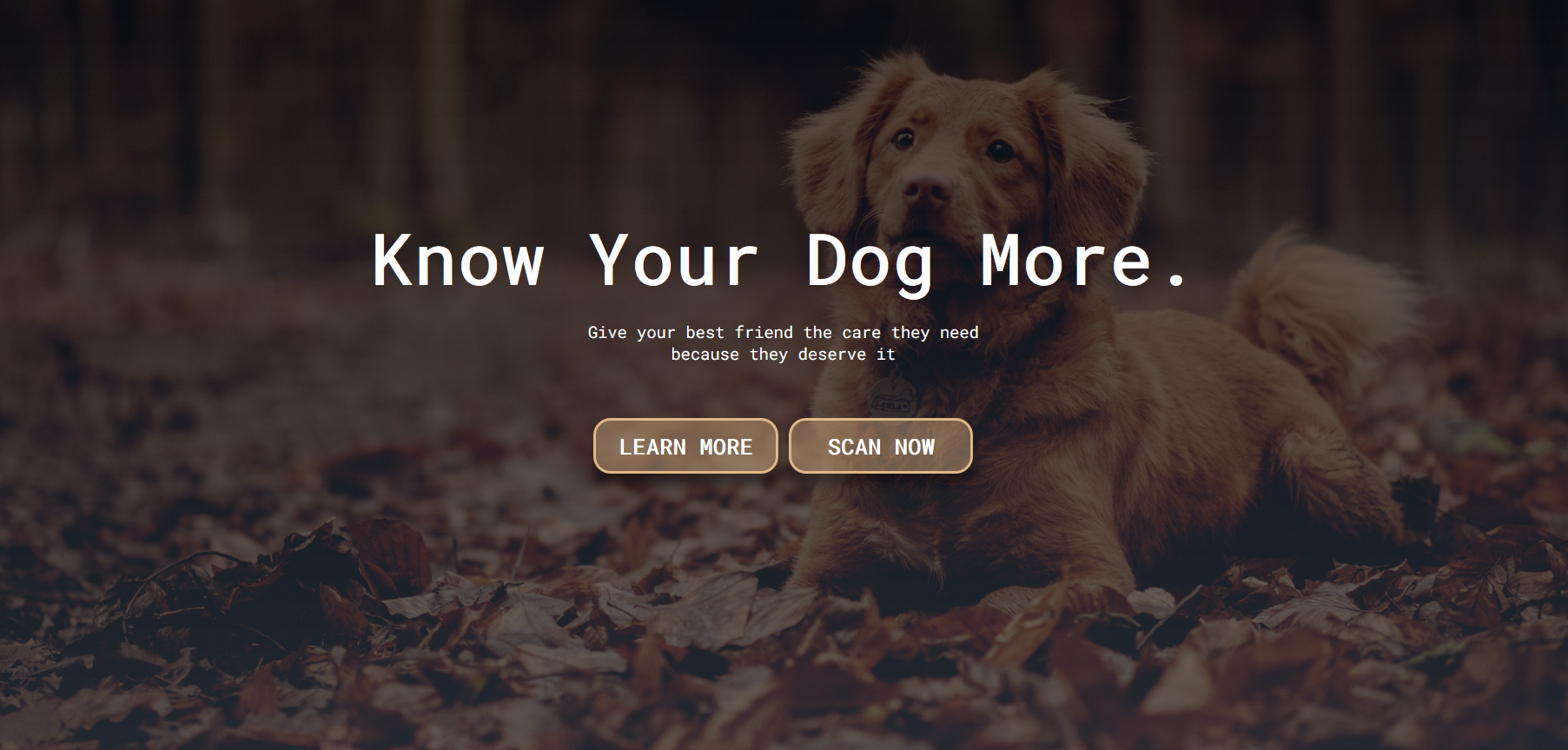
Similarly, a collapse menu was also designed for the website, when the window size is reduced further the menu options in the header will eventually collapse into a three-stack icon in the corner of the user's screen. This helps achieve a more commercialised website due to the user having full access to all the options that they would have on a desktop computer alongside a clear navigation to follow, which helps improve their experience with the website.
How was the machine learning model chosen?
During the development, the group determined that it would be best to use a pretrained model as it would drastically impact the accuracy, validity and confidence of it. For the application many pretrained models were reviewed, including Resnet50, Resnet50V2, VGG16, Xception alongside Densenet, these models were trialled rigorously. After final training, it was apparent that Resnet50V2 was the best due to it producing an accuracy of 71% when identifying the breed of the dog from the image uploaded, which was higher than the other models. Additionally, there were alterations with the variables the model made use of, due to issues regarding the application being able to correctly identify the breed of dog. One variable that was experimented with was the alteration of the batch sizes, which allowed the efficiency of the model to improve since the number of epochs coupled with how fast they were completed increased. Similarly, another variable that was altered was the optimiser as modifying this further, helped improve the efficiency of the model
How was the model made even more accurate?
Autotune
Prefetching performs a pipelining effect on the preprocessing and the model execution of a training step. Whilst the model is executing a step, the input pipeline is reading the data for the step ahead. Doing this allows for a quicker runtime and extraction of data from testing. You can set the value for the prefetch manually or you can use AUTOTUNE as the group have done here. This means the system will dynamically change the value during the runtime.

Data augmentation
We used data augmentation in the final product. To apply data augmentation, ‘Keras.Sequential’ was used to choose properties to which the group wanted to modify the data by. The images will then be modified randomly up to the values specified in the code. It was applied to the training set only, not the testing data. The AUTOTUNE function was used again but this time applying it to ‘num_parallel_calls’. This function will do a pipelining effect this time but on the preprocessing for the distorting the images. So multiple data augmentation modifications will apply overlapping each other.

Database
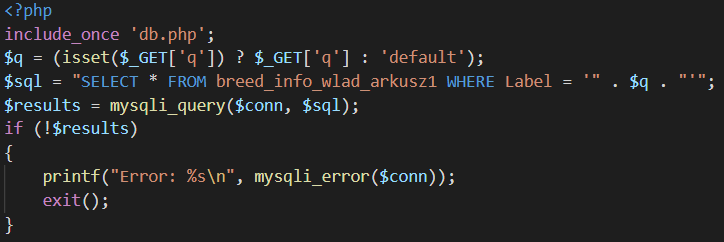
When a dog is recognized, information about the breed in the photo are displayed in a table below the uploaded image. Every team member got an even amount of breeds to collect data on and then they had to send their findings to me. I was responsible for making all of it into a SQL database, which then I connected to the PHP web app via MySQLi. Both the database and the app were hosted on Heroku, as it is the best practice to host both resources on the same platform.
Conclusion
This artifact was quite challenging to do because not only it consists of various fields in Computer Science (Front End development, databases, machine learning) but we also had other modules and uni work to do at the same time. The fact that
none of us knew anything about Machine Learning prior to working on this app didn't help either... However, we are very happy with how it turned out and hope you will like it too!
Give our website a try, scan a photo or two and
give us feedback through the form on the website, hope to see an email from you soon!